html、css先入门,即能够完成传统布局要求和常用属性即可,能完成淘宝或是京东的首屏,重点: BFC,盒模型;(有一定基础的可以直接跳过)
HTML5 和CSS3 ,做一个简单了解,HTML5 的核心: 存储相关,音视屏,canvas;
css3 核心: 动画,flex, 响应式布局
sass,less 选择其一作为了解对象,推荐sass;
JS 先从ECMAScript 开始,ECMAScript 中的核心概念,例如对象相关 --原型,原型链,继承 ; 函数相关 --预编译,作用域,作用域链,闭包,构造函数,this 指向; 基本类型相关: 包装类,隐式转化,数组方法等等;
DOM 部分 -- 基本操作,事件相关:事件级别,事件模型,事件流;尺寸相关: offset尺寸和client 尺寸; dom中的事件类型
简单了解网络,知道网络过程中作了些什么;
jQuery 简单理解和运用,了解链式操作的优势,jQuery 的工具函数,ajax;
ES6部分 查漏补缺,进一步加深对函数的理解,了解常用用法和核心, 结构赋值,箭头函数, promise 异步,ES6 module;
结合一些小的例子,接触一下函数式编程,和面向对象编程,接触即可,不要深究;
接触一下node,不用深究,了解node 能做什么,常用模块path, fs模块即可;
开始接触自动化工具,webpack,知道核心功能和常用配置即可;
git 工具入门;
开始可以接触框架了,如果觉得基础不错,可以接触react(推荐),如果一般的话就从vue开始,框架的学习;
通过框架的学习,查漏补缺,进一步对面向对象和函数式编程加深理解,尝试了解框架底层是怎么做到渲染的;
不断的实战,不同的实战,多整理,总结实战经验,建议写个小本本,记录实战的每一个问题,以及解决方案;
不要尝试去用更多的框架和工具,先选其一,作为主攻对象,当你对其中的一个框架,在源码上有一定认识后,在尝试用不同的工具;
在实战中,加深对网络的理解,进一步补充html5,css3 和dom的不足,ECMAScript 的不足点;
node 开始入门,http模块,event模块,开始接触一下,选express 作为后端框架开始入门
尝试做一些更有趣的东西;
简单的数据层面了解一下,知道数据库是什么,优势,选型,用node 如何操作;
网络开始系统了解,开始要搭自己的服务器了,能做的事就更多了;
到这里,可以开始拓展你前端的视野了,微信小程序,react native,ts,flutter,基础打的好的话,可以各种飞,剩余的路就是看你能飞多高了
诸君,路漫漫,共勉;
# HTML5
# web标准?
w3c(万维网联盟)
# <!DOCTYPE html>有什么用?说说meta标签?
文档类型声明标签:说明文档采用html5格式
lang--language文档语言
charset定义文本编码格式
# 一些常见标签?
p:段落标签 两段之间有空隙br:换行标签 单标签 简单换行无缝隙strong:强调标签 加粗

divspan
# 锚点链接
# 相对路径和绝对路径?
相对路径:

# 表格
table

# 列表
ul:unorderlistul>liol>li自定义列表:dl:definition list
dt:definition termdd:definition description
# 表单
表单域:
form属性:action method name表单控件:
inputtype:textpasswordradiocheckbox下拉:select>option默认被选中:selected="selected" submit文本域:
textarea
radio和checkbox需要注意的事情:定义相同name
label标签
for -> id
# CSS3
# 选择器
四种基本选择器
复合选择器
伪类选择器:遵循LVHA顺序
:focus伪类选择器主要用form表单 input:focus{}
# 引入方式
行内 内部 外部<link>标签style href
# 块元素

# 行内元素/内联元素

# 行内块元素

单行文字垂直居中:设置line-height = height
# 显示模式的转换
设置display:
# CSS三大特性
层叠性 继承性 优先级
# 盒子模型
width,height控制content内容大小
# 边框border
border-collapse:collapse 边框合并
Border影响盒子大小
圆角边框:border-radius:lenght
# 内边距padding
符合写法:3个:上 左右 下 4个:顺时针
padding会影响盒子大小
不指定宽高 不会撑开
# 外边距margin
设置盒子水平居中:1.设置宽度 2.设置左右外边距为auto
设置行内元素和行内块元素水平居中:父元素设置text-align:center
# 嵌套塌陷问题和BFC
嵌套塌陷问题三种解决方式:

# 传统网页布局三种方式
标准流/文档流
浮动
定位
# 浮动
# 浮动特性:脱标(脱离标准流)不再保留原来的位置
# 浮动元素会具有行内块元素的特性:
1.如果块级盒子没有设置宽度,默认宽度和父级一样宽,但是添加浮动后,它的大小根据内容来决定。 2.浮动的盒子中间是没有缝隙的,是紧挨着一起的。 3.行内元素同理。
# 浮动元素经常搭配标准流的父元素使用
# 一个元素浮动,按理来说其兄弟元素也要浮动
⚠️如果第一个兄弟元素为标准流,第二个为浮动,第二个会在第一个下面一行浮动因为第一个块元素独占一行。
即:浮动盒子只会影响浮动盒子后面的标准流而不会影响其前面的标准流。
# 清除浮动
策略:闭合浮动
1**.额外标签法也称为隔墙法**,是W3C推荐的做法。
在浮动元素末尾添加一个空的块级元素,给其添加属性style:clear:both
2.父级添加 overflow属性。(触发BFC)
3.父级添加 aftert伪元素。 4.父级添加双伪元素。
# 定位
定位组成:定位模式+边偏移
四种定位模式:
静态定位(无定位)
相对定位
绝对定位
固定定位
# 相对定位 position:relative
相对于自己原来位置进行偏移
原来在标准流的位置继续占有(不脱标)
典型应用:给绝对定位当爹
# 绝对定位 position:absolute
如果没有祖先元素或者祖先元素没有定位则相对于document定位
如果祖先有定位,则以最近一级有定位的祖先元素作为参考点移动位置
绝对定位不占有原来位置 (脱标)
# 子绝父相
为了让子元素绝对定位,所以让父亲相对定位
# 固定定位 position:fixed
# 粘性定位 position:sticky

# 定位叠放次序:z-index
数值可以是正整数,负数或者0;默认是auto
数值相同:按照书写顺序后来者居上
不能加单位
只有定位的盒子才能用此属性
# 绝对定位盒子居中
50%-二分之一宽/高
# 定位的特殊性

# 浮动和绝对定位的一点区别:
浮动会压住标准流的盒子但不会压住盒子里面的文字和图片而绝对定位都会压住
⚠️浮动最初是用来做文本环绕用的
# 显示与隐藏元素
# display显示与隐藏元素
display:none不显示元素 元素不再占有其他原来的位置,但是在html结构树中还存在
display:block 除了转换为块级元素之外,同时还有显示元素的意思
# visibility显示与隐藏元素
visibility:visible,元素可见
visibility:none,元素隐藏 隐藏后,继续占有原来的位置
# overflow显示与隐藏元素
对溢出的元素进行操作
visible 显示 (默认)
hidden 隐藏
scroll 滚动条
auto 在需要时添加滚动条
# 精灵图/雪碧图(sprites)
为了有效减少服务器接受和发送请求的次数,提高加载速度
主要针对背景图片使用,就是把多个小背景图片整合到一张大图片中 这个大图也称为sprites 精灵图 雪碧图


# 字体图标
展示的是图标,本质是字体
两个字体图标网站:
引用
替换:上传.json文件 重新选择 重新下载 替换原来文件
# 三角形的绘制
# 鼠标样式
style=“cursor:pointer”
# BFC(重点)
解决边框合并问题
# HTML5新特性
# 新增语义化标签

# 新增多媒体标签
video:mp4 webm ogg
audio: mp3 wav ogg
# 新增input表单
# 新增表单属性

# CSS3新特性
# 新增属性选择器
# 新增结构伪类选择器
结构伪类选择器主要根据文档结构来选择元素,常用于根据父级选择器里面的子元素
注意一下nth-child(n)和nth-of-type(n)的区别
# 新增伪元素选择器(重点)
css3写法 双冒号 照顾低版本:单冒号
::before 在元素内部的前面插入元素
::after 在元素内部的后面插入元素
2
before和after创建元素属于行内元素,想设置宽高需要转换类型
在文档树中是找不到的
语法:ele::before{}
before和after必须有content属性
和标签选择器一样权重为1
# border-sizing解决撑开盒子的问题
默认为content-box
盒子大小为width+padiing+border
border-box:大小为width
# calc函数
width:clac(100% - 30px) 注意:符号两端要加空格
# 新增属性过渡
transition:变化的属性 花费时间 运动曲线(默认esea 直线:linear) 何时开始
可以理解成当属性变化时(如通过伪类选择器:hover改变),通过transition属性设置成过渡变化
# 2D转换之translate rotate scale
# CSS3动画
分两步:
1.先定义动画
2.再使用(调动)动画
1.用@keyframe定义动画(类似定义类选择器)
eg:
@keyframe 动画名称 {
0%{
transform:translate(0,0);
},
100%{
transform:translate(100px,0);
}
}
2
3
4
5
6
7
8
百分比是给总时间的划分;除了使用百分比也可以使用from to相当于开始和结束
2.引用
animition-name:动画名称animition-duration:时间

# 3D转换
*3d
# 实战案例
# 移动端之flex布局(弹性布局/伸缩布局/弹性布局/弹性盒布局)
采用flex布局的元素,称为flex容器。它的所有子元素自动成为容器成员,称为flex项目。通过给父亲添加flex属性,来控制子盒子的位置和排列方式。
# 容器的属性
以下6个属性设置在容器上。
flex-directionflex-wrapflex-flowjustify-contentalign-itemsalign-content
# flex-direction属性
flex-direction属性决定主轴的方向(即项目的排列方向)。
.box { flex-direction: row | row-reverse | column | column-reverse; }1
2
3

它可能有4个值。
row(默认值):主轴为水平方向,起点在左端。row-reverse:主轴为水平方向,起点在右端。column:主轴为垂直方向,起点在上沿。column-reverse:主轴为垂直方向,起点在下沿。
# flex-wrap属性
默认情况下,项目都排在一条线(又称"轴线")上。flex-wrap属性定义,如果一条轴线排不下,如何换行。
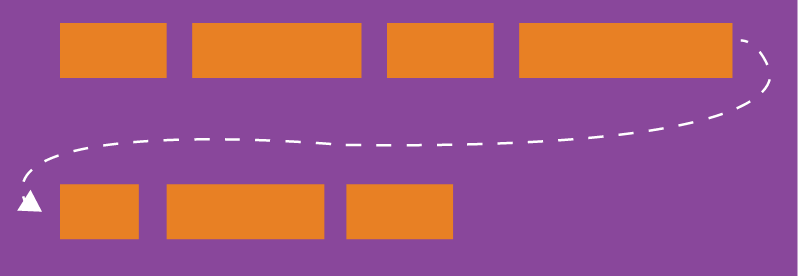
.box{ flex-wrap: nowrap | wrap | wrap-reverse; }1
2
3
它可能取三个值。
(1)nowrap(默认):不换行。

(2)wrap:换行,第一行在上方。

(3)wrap-reverse:换行,第一行在下方。

# flex-flow属性
flex-flow属性是flex-direction属性和flex-wrap属性的简写形式,默认值为row nowrap。
.box { flex-flow: <flex-direction> || <flex-wrap>; }1
2
3
# justify-content属性
justify-content属性定义了项目在主轴上的对齐方式。
.box { justify-content: flex-start | flex-end | center | space-between | space-around; }1
2
3

它可能取5个值,具体对齐方式与轴的方向有关。下面假设主轴为从左到右。
flex-start(默认值):左对齐flex-end:右对齐center: 居中space-between:两端对齐,项目之间的间隔都相等。space-around:每个项目两侧的间隔相等。所以,项目之间的间隔比项目与边框的间隔大一倍。
# align-items属性
align-items属性定义项目在交叉轴上如何对齐。
.box { align-items: flex-start | flex-end | center | baseline | stretch; }1
2
3

它可能取5个值。具体的对齐方式与交叉轴的方向有关,下面假设交叉轴从上到下。
flex-start:交叉轴的起点对齐。flex-end:交叉轴的终点对齐。center:交叉轴的中点对齐。baseline: 项目的第一行文字的基线对齐。stretch(默认值):如果项目未设置高度或设为auto,将占满整个容器的高度。
# align-content属性
align-content属性定义了多根轴线的对齐方式。如果项目只有一根轴线,该属性不起作用。
.box { align-content: flex-start | flex-end | center | space-between | space-around | stretch; }1
2
3

该属性可能取6个值。
flex-start:与交叉轴的起点对齐。flex-end:与交叉轴的终点对齐。center:与交叉轴的中点对齐。space-between:与交叉轴两端对齐,轴线之间的间隔平均分布。space-around:每根轴线两侧的间隔都相等。所以,轴线之间的间隔比轴线与边框的间隔大一倍。stretch(默认值):轴线占满整个交叉轴。
# 项目的属性
以下6个属性设置在项目上。
orderflex-growflex-shrinkflex-basisflexalign-self
# order属性
order属性定义项目的排列顺序。数值越小,排列越靠前,默认为0。
.item { order: <integer>; }1
2
3
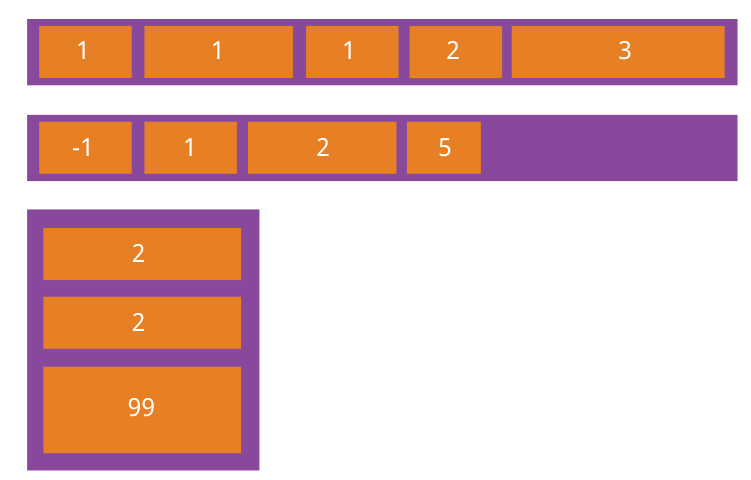
# flex-grow属性
flex-grow属性定义项目的放大比例,默认为0,即如果存在剩余空间,也不放大。
.item { flex-grow: <number>; /* default 0 */ }1
2
3

如果所有项目的flex-grow属性都为1,则它们将等分剩余空间(如果有的话)。如果一个项目的flex-grow属性为2,其他项目都为1,则前者占据的剩余空间将比其他项多一倍。
# flex-shrink属性
flex-shrink属性定义了项目的缩小比例,默认为1,即如果空间不足,该项目将缩小。
.item { flex-shrink: <number>; /* default 1 */ }1
2
3

如果所有项目的flex-shrink属性都为1,当空间不足时,都将等比例缩小。如果一个项目的flex-shrink属性为0,其他项目都为1,则空间不足时,前者不缩小。
负值对该属性无效。
# flex-basis属性
flex-basis属性定义了在分配多余空间之前,项目占据的主轴空间(main size)。浏览器根据这个属性,计算主轴是否有多余空间。它的默认值为auto,即项目的本来大小。
.item { flex-basis: <length> | auto; /* default auto */ }1
2
3
它可以设为跟width或height属性一样的值(比如350px),则项目将占据固定空间。
# flex属性
flex属性是flex-grow, flex-shrink 和 flex-basis的简写,默认值为0 1 auto。后两个属性可选。
.item { flex: none | [ <'flex-grow'> <'flex-shrink'>? || <'flex-basis'> ] }1
2
3
该属性有两个快捷值:auto (1 1 auto) 和 none (0 0 auto)。
建议优先使用这个属性,而不是单独写三个分离的属性,因为浏览器会推算相关值。
# align-self属性
align-self属性允许单个项目有与其他项目不一样的对齐方式,可覆盖align-items属性。默认值为auto,表示继承父元素的align-items属性,如果没有父元素,则等同于stretch。
.item { align-self: auto | flex-start | flex-end | center | baseline | stretch; }1
2
3

该属性可能取6个值,除了auto,其他都与align-items属性完全一致。
# SASS
sass->scss
四种模式
变量:使用**$符号**进行定义变量和引用变量,如果是字符串需要加双引号
嵌套写法
引用父选择器 冒号
使用伪类选择器直接使用引号会产生空格 所以要使用**@符号**在在前面
@mixin
混合 可以理解成一个模块或者是函数 结构为**@mixin+名字** 引用时使用@inlude名字
混合后面可以跟括号加参数 参数和变量的定义是一样的 调用时和函数调用类似
混合内也可以嵌套
继承/扩展 在样式里使用**@extend 父样式**
@import
使用import 引用partials partials文件使用下划线开头命名 在引用时不加下划线 如 @import "base";
数据类型
- 数字
- 8/2 一般被认为是字号和行间距 所以数字的除法要加上括号
- 乘法不能同时带px
- 数字函数
- abs round ceil floor percentage min max
- 字符串
- 列表
- 颜色
interpolation
#{@名称}
@if
@for

through 包括结束值
to 到结束值立即停止循环
@each

**@while**
函数
警告与错误
# JavaScript
# ECMAScript
ECMAScript是一个标准,JS只是它的一个实现,其他实现包括ActionScript。 “ECMAScript可以为不同种类的宿主环境提供核心的脚本编程能力……”,即ECMAScript不与具体的宿主环境相绑定,如JS的宿主环境是浏览器,AS的宿主环境是Flash。 ECMAScript描述了以下内容:语法、类型、语句、关键字、保留字、运算符、对象。
# 数据类型
基本数据类型
Number String Boolean Null Undefined (ES6新增:Symbol和Bigint)
存储在栈
引用数据类型
Object Function Array
存储在堆
console.log(typeof (null));//Object 特殊 二进制前三位为0被判断成Null类型
console.log(typeof (Null));//Undefined
console.log(typeof (Number.MAX_VALUE));//Number
console.log(typeof (Number.MAX_VALUE * (-1)),Number.MAX_VALUE * (-1));//Number Infinity
console.log(typeof (Object));//Function
console.log(typeof (Function));//Function
console.log(typeof (Number));//Function
console.log(typeof (false));//Boolean
console.log(typeof (undefined));//Undefined
console.log(typeof (Boolean));//Function
console.log(typeof (String));//Function
console.log(typeof (Undefined));//Undefined
2
3
4
5
6
7
8
9
10
11
12
# 强制类型转换
# 变量提升
# this
- 在方法中,
this表示该方法所属的对象。 - 如果单独使用,
this表示全局对象。 - 在函数中,
this表示全局对象。 - 在函数中,在严格模式下,
this是未定义的(undefined)。 - 在事件中,
this表示接收事件的元素。 - 类似
call() 和apply() 方法可以将this引用到任何对象。
# 预解析
# 构造函数和类的关系
# 原型


使用hasOwnProperty()方法来判断属性是否属于原型链的属性
# 闭包
let解决for循环问题
- 与for的关系
- var 初始变量在for循环体内,是覆盖式的,用C的话来讲是共用体,即共用同一内存地址
- let初始变量在每一次for循环中,都是一个独立的变量,拥有自己独立的内存地址。
- 函数体内部引用了内部不存在的变量,会寻找上层作用域 (opens new window)内的同名变量
闭包用途
- 读取函数内部的变量
- 让这些变量的值始终保持在内存中。不会再f1调用后被自动清除。
- 方便调用上下文的局部变量。利于代码封装。
原因:f1是f2的父函数,f2被赋给了一个全局变量,f2始终存在内存中,f2的存在依赖f1,因此f1也始终存在内存中,不会在调用结束后,被垃圾回收机制回收。
# 执行上下文
简单来说执行上下文就是指: 在执行一点JS代码之前,需要先解析代码。解析的时候会先创建一个全局执行上下文环境,先把代码中即将执行的变量、函数声明都拿出来,变量先赋值为undefined,函数先声明好可使用。这一步执行完了,才开始正式的执行程序。 在一个函数执行之前,也会创建一个函数执行上下文环境,跟全局执行上下文类似,不过函数执行上下文会多出this、arguments和函数的参数。
全局上下文:变量定义,函数声明 函数上下文:变量定义,函数声明,this,arguments
# DOM
# HTMLCollection和NodeList的相同点和异同点
他们都不是数组无法使用数组的那些方法
NodeList 对象类似 HTMLCollection (opens new window) 对象。
一些旧版本浏览器中的方法(如:getElementsByClassName())返回的是 NodeList 对象,而不是 HTMLCollection 对象。
所有浏览器的 childNodes 属性返回的是 NodeList 对象。
大部分浏览器的 querySelectorAll() 返回 NodeList 对象。
HTMLCollection (opens new window) 是 HTML 元素的集合。
NodeList 是一个文档节点的集合。
NodeList 与 HTMLCollection 有很多类似的地方。
NodeList 与 HTMLCollection 都与数组对象有点类似,可以使用索引 (0, 1, 2, 3, 4, ...) 来获取元素。
NodeList 与 HTMLCollection 都有 length 属性。``
HTMLCollection 元素可以通过 name,id 或索引来获取。
NodeList 只能通过索引来获取。
只有 NodeList 对象有包含属性节点和文本节点。
# BOM
# windows是顶层对象
所有对象都是通过window延伸出来的,也称为window的子对象
# BOM五大对象:
Document 文档对象——整个浏览器窗口区域
History 从窗口被打开起的历史记录
Location 当前窗口中加载的文档有关的信息
Navigator 浏览器本身的信息,浏览器的版本、名称等等
Screen 有关客户端屏幕的信息
# ES6
# let和const
变量提升
块级作用域
相同点区别
# 模版字符串
# 解构
数组解构
对象解构
函数解构
# 函数的扩展
rest参数
ES6 引入 rest 参数(形式为
...变量名),用于获取函数的多余参数,这样就不需要使用arguments对象了。rest 参数搭配的变量是一个数组,该变量将多余的参数放入数组中。
箭头函数
参数=>返回值
注意点
# 对象的扩展
promise对象
三种状态
resolve方法reject方法then方法catch方法race方法all方法
async函数

# ESmodule
export
import
import {name,age,color,sayName,fn} from './modules/index.js';
import * as obj from './modules/index.js';
2
3
# Jquery和Ajax
# jquery中的$(function(){...})什么时候执行
这个是在页面DOM文档加载完成后加载执行的,等效于$(document).ready(function(){...}); 优于window.onload,后者必须等到页面内包括图片的所有元素加载完毕后才能执行。
# jquery中的ajax封装
eg:1
$.ajax({
type: "get",// get或者post
url: "abc.php",// 请求的url地址
data: {},//请求的参数
dataType: "json",//json写了jq会帮我们转换成数组或者对象 他已经用JSON.parse弄好了
timeout: 3000,//3秒后提示错误
beforeSend: function () {
// 发送之前就会进入这个函数
// return false 这个ajax就停止了不会发 如果没有return false 就会继续
},
success: function (data) { // 成功拿到结果放到这个函数 data就是拿到的结果
},
error: function () {//失败的函数
},
complete: function () {//不管成功还是失败 都会进这个函数
}
})
// 常用
$.ajax({
type: "get",
url: "",
data: {},
dataType: "json",
success: function (data) {
}
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
eg2:
$(function(){
//请求参数
var list = {};
//
$.ajax({
//请求方式
type : "POST",
//请求的媒体类型
contentType: "application/json;charset=UTF-8",
//请求地址
url : "http://127.0.0.1/admin/list/",
//数据,json字符串
data : JSON.stringify(list),
//请求成功
success : function(result) {
console.log(result);
},
//请求失败,包含具体的错误信息
error : function(e){
console.log(e.status);
console.log(e.responseText);
}
});
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# Vue
# Vue的基本概念
# Vue是一个渐进式的js框架
渐进式:可以逐渐在项目中使用Vue
# 框架:
库:一系列函数的集合,不提供逻辑,需要程序员自己处理
框架:一整套完整的解决方案,框架回帮我们实现大部分的代码,只要在合适的地方书写代码
框架比库更加强大,要求也更多
# Vue的基本使用步骤
# 下载Vue.js
# 引入Vue
创建Vue 实例
const vm = new Vue({})
# 指定el和data
el:不能指定body和html
data:就是一个对象,提供数据
methods:提供方法
# Vue的差值表达式
# 概念
小胡子语法 mustache语法
# 作用
访问data 中的数据,显示在标签的内容里
# 注意点
访问的数据必须在data中存在
不能使用语句,出现if for
不能在属性中使用
# Vue的指令
# 指令
就是Vu额提供的一堆自定义的html的属性,这些属性都是以v-开头的
# 指令的作用
每个指令都有特殊的作用(指令的整体作用:不让用户直接操作DOM而是操作数据)
# v-bind
作用:
让标签的属性中访问data中的数据
用法:
v-bind:title = 'title'
:title = 'title'
title = 'title'注意点:
2
3
注意:
访问的数据应该在data中存在
# v-model
作用:
给表单元素添加,实现双向数据绑定
用法:
<input v-model = "msg">
面试问双向数据绑定如何实现:
数据发生了改变->视图跟着变 数据的劫持 兼容IE8以下使用angular1轮询
let temp = data.msg
defineProperty(data,'msg',{
get(){
return temp
}
set(value){
temp = value
input.value = temp
}
})
2
3
4
5
6
7
8
9
10
11
12
13
14
视图发生了改变->数据跟着变 注册表单事件
注意点:
只能表单元素添加
v-model会忽略掉原本的value值
# v-on
作用:
注册事件
用法:
v-on:click = "clickFn"
@click = "clickFn"
2
注意点:
方法必须在methods属性中提供
methods中的this绑定为当前的vm实例 不能箭头函数
# 计算机网络
# 网络模型
# OSI七层模型
从下往上:
物理层-数据链路层-网络层-传输层-会话层-表示层-应用层

OSI七层模型通信特点:对等通信
# TCP/IP五层协议
三合一
一般交换机、网桥、网卡工作在数据链路层
一般路由器工作在网络层
# TCP和UDP
# UDP-用户数据报协议
# TCP-传输控制协议
拥塞控制:
慢启动 拥塞避免算法
快速重传:失序后三次重复确认就立即重传
快速恢复(顺序):加法增大 乘法减小 不尽兴慢启动直接进入拥塞避免算法
流量控制:
一般来说,流量控制就是为了让发送方发送数据的速度不要太快,要让接收方来得及接收。TCP采用大小可变的滑动窗口进行流量控制,窗口大小的单位是字节。这里说的窗口大小其实就是每次传输的数据大小。
- 当一个连接建立时,连接的每一端分配一个缓冲区来保存输入的数据,并将缓冲区的大小发送给另一端。
- 当数据到达时,接收方发送确认,其中包含了自己剩余的缓冲区大小。(剩余的缓冲区空间的大小被称为窗口,指出窗口大小的通知称为窗口通告 。接收方在发送的每一确认中都含有一个窗口通告。)
- 如果接收方应用程序读数据的速度能够与数据到达的速度一样快,接收方将在每一确认中发送一个正的窗口通告。
- 如果发送方操作的速度快于接收方,接收到的数据最终将充满接收方的缓冲区,导致接收方通告一个零窗口 。发送方收到一个零窗口通告时,必须停止发送,直到接收方重新通告一个正的窗口。
TCP粘包:
下面看⼀个例⼦, 连续调⽤两次 send 分别发送两段数据 data1 和 data2, 在接收端有以下⼏种常⻅的情况: A. 先接收到 data1, 然后接收到 data2 . B. 先接收到 data1 的部分数据, 然后接收到 data1 余下的部分以及 data2 的全部. C. 先接收到了 data1 的全部数据和 data2 的部分数据, 然后接收到了 data2 的余下的数据. D. ⼀次性接收到了 data1 和 data2 的全部数据。
其中的 BCD 就是我们常⻅的粘包的情况. ⽽对于处理粘包的问题, 常⻅的解决⽅案有:
- 多次发送之前间隔⼀个等待时间:只需要等上⼀段时间再进⾏下⼀次 send 就好, 适⽤于交互频率特别低的场景. 缺点也很明显, 对于⽐较频繁的场景⽽⾔传输效率实在太低,不过⼏乎不⽤做什么处理。
- 关闭 Nagle 算法:关闭 Nagle 算法, 在 Node.js 中你可以通过
socket.setNoDelay() ⽅法来关闭 Nagle 算法, 让每⼀次 send 都不缓冲直接发送。该⽅法⽐较适⽤于每次发送的数据都⽐较⼤ (但不是⽂件那么⼤), 并且频率不是特别⾼的场景。如果是每次发送的数据量⽐较⼩, 并且频率特别⾼的, 关闭 Nagle 纯属⾃废武功。另外, 该⽅法不适⽤于⽹络较差的情况, 因为 Nagle 算法是在服务端进⾏的包合并情况, 但是如果短时间内客户端的⽹络情况不好, 或者应⽤层由于某些原因不能及时将 TCP 的数据 recv, 就会造成多个包在客户端缓冲从⽽粘包的情况。 (如果是在稳定的机房内部通信那么这个概率是⽐较⼩可以选择忽略的)。 - 进⾏封包/拆包: 封包/拆包是⽬前业内常⻅的解决⽅案了。即给每个数据包在发送之前, 于其前/后放⼀些有特征的数据, 然后收到数据的时 候根据特征数据分割出来各个数据包。